2025年6月現在、
SEOやWeb界隈で新たな話題として急浮上しているのが「llms.txt」というファイル。これは、サイト所有者が自分のサイトをAIモデル(特にGPTなどの大規模言語モデル=LLM)に効率よく理解させるための仕組みです。
具体的には、サイト内の重要なコンテンツをMarkdown形式でわかりやすくまとめ、このllms.txtというファイルをサイトのルートディレクトリに設置することで、AIが無駄なHTMLやスクリプトを無視してサイトの本質的な情報にすばやくアクセスできるようにするというもの。
この提案をしたのは、Fast.aiやAnswer.AIの共同創設者であるジェレミー・ハワード氏です。彼は2024年9月3日にこのアイデアを発表しました。
現在のLLMの課題の一つは「コンテキストウィンドウ」と呼ばれる情報の処理上限です。つまり、AIは長く複雑なページを一度に処理するのが苦手であり、その結果、本当に大切な情報を見落としてしまうことがあります。llms.txtは、この問題を根本的に解決する可能性を秘めているため、多くの開発者やSEO専門家が注目し始めました。
しかし..
このような新しい言説やトレンドを実際の検証や評価もなしに盲目的に信じ、即座に対応を依頼するのは非常に愚かな行動と言えます。なぜなら、実際に詳細な検証や分析を行うと、ほとんどの場合、初期に騒がれた言説と実際の結果は一致せず、むしろ異なることが常だからです。まずは冷静に情報を精査し、根拠に基づいた判断を下すことが何より重要です。
少し立ち止まって考えてみれば容易にわかることではあります。
経済活動の多くは性悪説で成り立っていることも多いです
AIOといって、事業者が都合の良い情報llms.txtに書くことがハックとして蔓延します
AIのクローラーとしては現在特別llmsをみてるわけではないのに精度高くまとめることができています
それなのに、なぜllmsを見るのか、ユーザエクスペリエンスの観点でもデメリットしかないです。
LLM(大規模言語モデル)の進化は著しく、特に「コンテキストウィンドウ」(一度に処理できる情報量)の上限が急速に拡大しています。
コンテキストウィンドウの拡大の現状
従来のモデル(GPT-3初期)は約2,048トークン(およそ1,500語)程度の制限が一般的でしたが、最近では以下のように大幅に拡大しています。
Claude 3 (Anthropic) や Gemini (Google DeepMind) などの最新モデルでは、数十万トークン規模の処理を実現しつつあります。
GPT-3.5 Turbo(初期):約4,096トークン
GPT-4:通常モデルで8,192トークン、拡張モデルでは32,768トークンまで対応可能
情報の処理上限?日々今を上回ってるんだよwという感じです。
そもそも、なぜllms.txtというアイデアが提唱され始めたのかというと、単純に「AIがより良くWebの内容を理解できるようにしたい」という技術的な意図に起因します。
しかしながら、実際にはインターネット上の情報というのは、本質的に性悪説に基づく部分も大きいのです。すなわち、多くの経済活動は「自分の利益を最大化する」動機に支配されており、その結果、事業者は自身に都合の良い情報をllms.txtに記載し、AIモデルを意図的に操作しようという行動に出る可能性があります。これが蔓延すれば、AIO(AI最適化)という言葉が生まれるほどにサイトの情報が歪曲され、かえってユーザーに不利益を与えかねません。
現状、GPTをはじめとするAIモデルは、特にllms.txtのようなファイルを参照せずとも、高度なクローリングと分析によってWebサイトのコンテンツを精度高くまとめられています。むしろ、人工的に提供されるllms.txtだけを鵜呑みにすると、事業者側の恣意的な操作によりAIの回答の精度が著しく低下する可能性があり、先ほども言いましたが、ユーザーエクスペリエンスの観点から見てもデメリットしかありません。
にもかかわらず、なぜllms.txtの導入を声高に主張する動きが出てきたのでしょうか。
それは、起源として主張されている、事業者のAIの協力関係とは別に、
AIの理解力向上という建前の裏に、AIを活用した新たなマーケティングやSEOの商機を狙った一部事業者や技術者のビジネス的な動機があるというのが本音ではないでしょうか。
(でなければただの言説を盲目的に信じているだけの状態ですよね。)
つまり、llms.txtの推進というのは、表面的にはAIの進化を目的としながらも、実態としては事業者側に有利な「新しいハック」を生み出そうとする意図と、それを見据えて「いずれみるかもしれない」という心理からの保険実装となっていると考えられます。
でも普通に考えれば、
現在のAI技術は、膨大な自然言語処理能力と文脈理解力を持っており、人為的な誘導がない場合にむしろ最も正確な情報を収集できます。これに対して、llms.txtのような「人間が用意した要約ファイル」に頼ってしまうと、意図的な情報操作や偏りが混入し、AIの本来の優位性を失ってしまうでしょう。
結局のところ、このような動きを推進している人々の動機を冷静に見れば、「ユーザーのため」という名目でありながら、実際には事業者自身が簡単にAIから注目を集められるようになるための手段に他なりません。安易な流行や一見便利そうな技術に飛びつくのではなく、現実的な検証や議論を経て慎重に判断すべきです。
我々はこれまで何度も繰り返されてきた歴史から学び、新しい技術や標準を採用する際には、表面的な利益だけにとらわれることなく、本質的なユーザー体験の向上や公平性を追求しなければならないのです。
そうです。
検 証 を し ま し ょ う 。
本当に検証をするという姿勢が重要です。
この「本当に検証をしてみる」といった一歩を踏み出す事業者は極めて少ないことを知っています。
GPTに弊社のサイトの”URL”を調べさせたらこれが結果でした。

この画像は間違っていますが、
実際に検索するとでてきます。
無関係な画像がでてきます。
つまり、googleの検索の画像でまとまってる部分も直接みています。
それだけではありません。
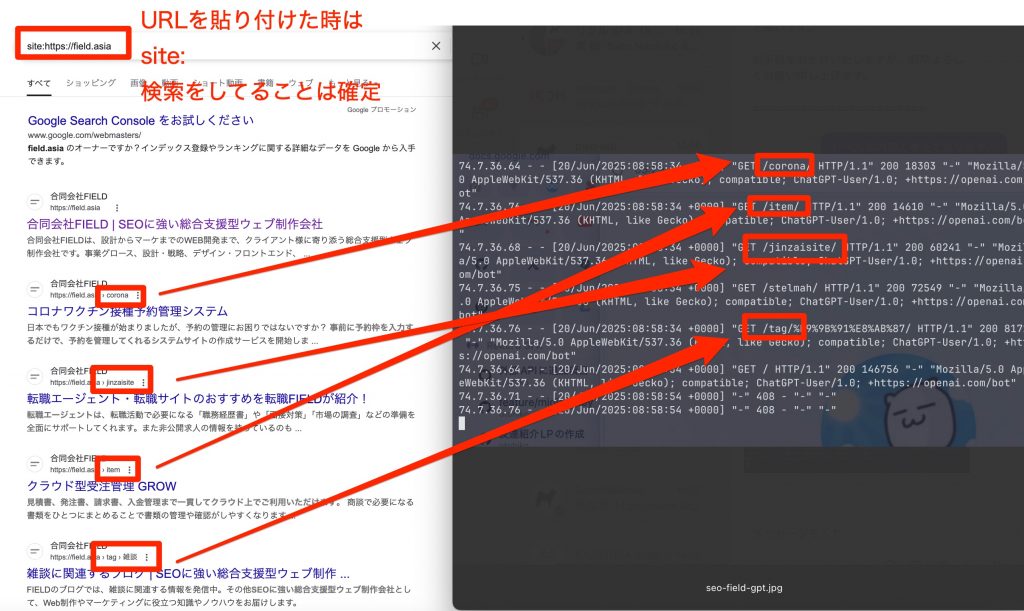
「site: 検索」をしていることがわかりました。
GPTがだしてる結果は実は弊社のサイトのTOPからは到達しないページです。
古い情報ばかりです。
しかしsite:検索をするとでてきます。
完全に一致をしていました。
同じスレッドでもう一度「もっと詳しくこの会社を知りたい」と聞いた時、GPTからのアクセスログは記録されませんでした。
その一連の会話の履歴の中では
2回、3回と毎回クロールすることはしません。
一度で文章を保有し、その中からまとめていることもわかりました。
では、違うブラウザやIPから2時間、時間をおいてもう一度検索したらどうなるのでしょうか
それは、もう一度アクセスがありました。そしてURLではなくて、会社名にしたら、TOPにのみアクセスがありました。


ではあまり時間をあけずに国を変えて、WIFIをかえて何度もGPTにサーチさせたらどうなるのでしょうか、
それは、一度もアクセスログに来ませんでした。
物理的にバンコクや東京で「合同会社FIELDについて調べて欲しい」と送っても
同じ会社の情報はどこかにストックされているのか、
アクセスはまったく確認されませんでした。(でも結果はでています。)
次にNotebooklmで「field.asia」にアクセスしました。
しかもllms.txtに以下を記載した状態です。
# 合同会社FIELD(FIELD LLC)
> 企業のブランド戦略、デジタルマーケティング、コンテンツ制作、メディア運営を通じて、
> クライアント企業の価値最大化と持続的な成長支援を目指す総合支援サービスプロバイダーです。
## 提供サービス
- [設計戦略](https://field.asia/business-growth/strategy/):ブランド構築・強化のための戦略策定支援
- [デザイン](https://field.asia/business-growth/design/):WEBデザインで企業を支える
- [LINE拡張サービス](https://field.asia/line/):店舗向けのLINE拡張ツール
## 特に力を入れてる
- [LINE拡張サービスによるマーケティングオートメーション](https://field.asia/line/):リピート率350%アップ
## 会社情報
- [会社概要](https://field.asia/about-us/)
## 更新日
2025年6月20日上記の様に、
内容をLINE拡張ツールを押してる様にミスリードしたものを設置します。
この状態でアクセスすると。。。

TOPのみのアクセスとなりました。
notebooklmは確実にllms.txtを見ていません。
次にGPTのDeepresearchを実行してみました。
そのログはこちらです。
結果はこれ
llms.txtは何もみていないですね
それもそのはずです。
なぜなら、
ログでもdeepresearchですら、llms.txtはアクセスしていないからです!

さまざまなページを回遊してるのがわかりますが、
結論llms.txtは一切アクセスがありませんでした。
それよりも特筆するべきはuser agentです。
Mozilla/5.0 (Macintosh;Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36
botと書いていない。
本当のユーザのように見に来ます。
やってきてますね。
AIOの世界が今後どうなるのかもう答えは今回の趣旨とは別に見えてきましたね。
また、現状llms.txtはまったく使われていません
1pxも使われていません。ゼロですよ。
これだけ騒がれていてゼロって転げ落ちるレベルではないですか。
最後にこのブログをそのまま全コピして、
なぜllms.txtが話題になってるのかをAIに聞きました。

「そのSEOパラメータの、ソースはどこですか?」「SEOのN+1の結果のどこにそのデータがありますか?」
SEOのときからさまざまなこのような意見を聞いてきましたが。
弊社が保有しています。
弊社には50万サイト以上の分析データが保有されています。
その分析結果に基づいたSEOとAIOを提供します。
今の経験が浅い事業担当者やマーケターは、
誰かが「AIの登場でgoogleの検索数が落ちた」といったら盲目的にそうだそうだとなってしまう。
どのようなサイトのどのようなアクションを目的を持つサイトで、どの数字が落ちたのか、またそれは一つだけに限った話か、類似の事例でも当てはまるのか、全く違う業界では?..という粒度細かく認識することができていないケースに遭遇します。
このような姿勢は感情的な意思決定隣安く、データドリブンで本質的なグロースマーケティングを阻害します。
答えをすぐに求めることは楽でいいのですが、
あらゆる言説には、「サイエンス」が必要です。
比喩ではなく本当に2週間に一回はAIが進化しています。
スタンダードも変わり続けるAIとマーケティングの中で
「サイエンス」の姿勢は一層重要になってきます。