AI検索ロジック完全解説
クローリング・言い換え・重みづけの全貌
AIが検索を実行するとき、従来の検索エンジンとはまったく異なるプロセスが動いている。本記事では、AIクローラの巡回メカニズムから、キーワード言い換え展開、エビデンス重みづけ、最終選定アルゴリズムまでを技術的に完全解説する。
AI検索時代のSEOは「言い換えロジック」に変わった
2024年以降、検索体験は急速に変化している。Google SGE(Search Generative Experience)、Bing Copilot、Perplexity、ChatGPTのWebブラウジング機能——これらのAI検索は、従来のキーワードマッチング型検索とは根本的に異なるプロセスで情報を収集・評価・統合している。
従来のSEOが「ユーザーが入力するキーワードをページに含める」ことに注力していたのに対し、AI検索時代のSEOではAIが内部で生成する言い換えキーワード群にどれだけ対応できるかが勝敗を分ける。
本記事では、この「AIの検索ロジック」を以下の5つのフェーズに分解し、それぞれの内部動作を技術的に深掘りする。
本記事の対象読者: SEO/AIO施策を実務で担当するマーケター、Web開発者、コンテンツ戦略担当者。AIの内部ロジックを理解することで、従来のSEO施策との差分を明確にし、具体的なアクションにつなげることを目的とする。
AIクローリングの内部メカニズム
AI検索がWebから情報を取得するプロセスは、Googlebot等の従来型クローラとは根本的に異なる。従来型クローラが「リンクを辿って網羅的にインデックスする」のに対し、AIクローラは「意図に基づいて選択的にクロールする」。
2-1. 従来型クローラとの根本的な違い
従来のGooglebot等のクローラは、リンクグラフ(PageRank)に基づいてWebを巡回する。リンクが多く張られたページから優先的にクロールし、新しいリンクを発見するたびにクロールキューに追加する——このプロセスは本質的に「構造ベース」の巡回である。
一方、AIクローラは「意味ベース」で巡回する。具体的には以下の点が異なる。
| 比較軸 | 従来型クローラ(Googlebot等) | AIクローラ(LLMベース) |
|---|---|---|
| 巡回トリガー | リンク発見・サイトマップ・定期巡回 | ユーザークエリの意図に基づくオンデマンド巡回 |
| 対象選定 | PageRank・ドメイン権威性・クロールバジェット | 意味的関連性・言い換え展開によるキーワードマッチ |
| 情報抽出 | テキスト全文インデックス・構造化データ | 文脈理解に基づくセマンティック抽出 |
| 評価基準 | 被リンク数・コンテンツ品質シグナル・UX指標 | エビデンスの信頼性・情報の一貫性・ソース多様性 |
| 結果形式 | ランキング付きリンクリスト(10 blue links) | 統合された自然言語回答+引用 |
2-2. AIクローラのリアルタイム巡回プロセス
AIクローラがクエリを受け取ってから実際にWebを巡回するまでのプロセスを、さらに細分化して解説する。
Phase A: クエリ前処理(Query Preprocessing)
ユーザーの自然言語入力を受け取ると、まず意図分類(Intent Classification)が行われる。これは「情報探索型」「ナビゲーション型」「トランザクション型」「比較検討型」などにクエリを分類するプロセスであり、この分類結果が後続の言い換え展開の方向性を決定する。
例えば「転職エージェント おすすめ」というクエリに対して、AIは以下のように意図を解析する。
- 主意図: 比較検討型(複数の選択肢から最適なものを選びたい)
- エンティティ: 「転職エージェント」= 人材紹介サービスカテゴリ
- 修飾語: 「おすすめ」= 品質フィルタ(高評価・人気のもの)
- 暗黙の意図: ランキング形式の情報を求めている、実体験ベースの情報が好まれる
- ユーザーペルソナ推定: 転職を検討中の社会人(20代後半〜40代)
Phase B: 検索クエリ生成(Search Query Formulation)
意図解析の結果を受けて、AIは実際にWeb検索を実行するための複数のクエリを自動生成する。これが従来の検索との最大の違いである。ユーザーが1つのクエリを入力しても、AIは内部で5〜20個の異なるクエリを生成し、それぞれで検索を実行する。
Phase C: マルチソース並列取得(Multi-Source Parallel Fetching)
生成された複数のクエリは、並列的に複数のソースに対して実行される。検索API(Google/Bing)の呼び出し、既知のURLへの直接アクセス、ナレッジベースの参照が同時に行われ、得られた結果は統合パイプラインに送られる。
重要な技術的示唆: AIクローラは「1クエリ = 1検索」ではない。1つのユーザークエリに対して、AIは内部で最大20以上の検索を並列実行し、その結果を統合的に評価する。つまり、AIに選ばれるためには、言い換え後のキーワード群のうち複数にヒットするコンテンツである必要がある。
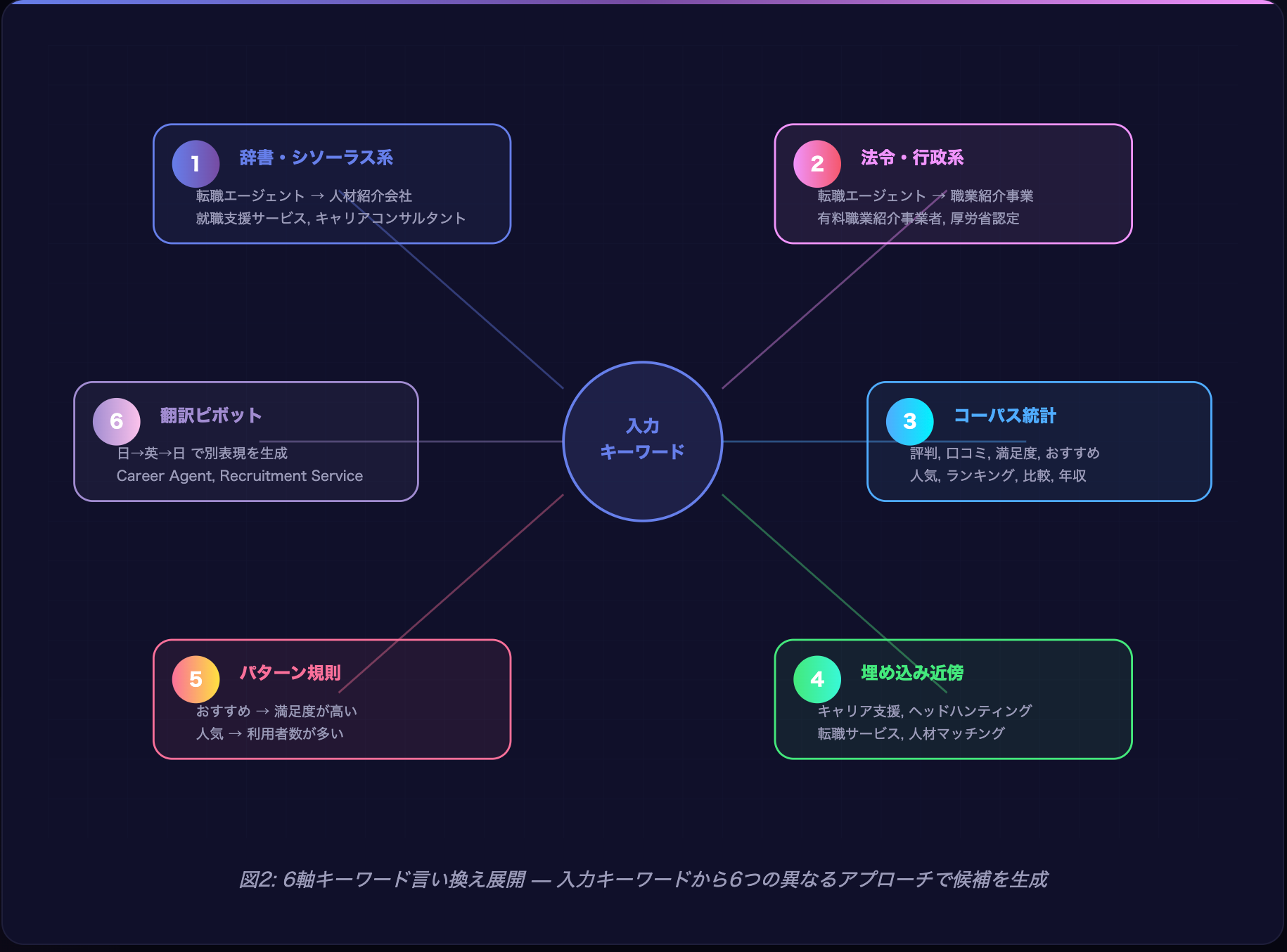
AIが行う「言い換え展開」の6つの手法
AIは、入力されたキーワードに対して以下の6つの異なる軸で言い換えを展開する。これは単純なシソーラス(類義語辞書)の参照にとどまらず、法令用語への変換、統計的共起分析、ベクトル空間上の近傍探索、規則ベースの変換、さらには多言語ピボットまで含む包括的な展開プロセスである。
3-1. 辞書・シソーラス系展開
最も基本的な言い換え手法であり、WordNet、日本語シソーラス、業界専門用語辞書等を参照して類義語・上位語・下位語を取得するプロセスである。
AIが参照するシソーラスは一般的な辞書にとどまらない。ドメイン特化型のオントロジー(医療ならMeSH、法律ならJST科学技術用語シソーラス等)も含まれており、専門分野のキーワードについても精度の高い言い換えが可能になっている。
- 同義語: 人材紹介会社、転職支援会社、人材紹介サービス
- 上位語: 人材サービス、雇用支援サービス
- 下位語: ハイクラス転職エージェント、IT特化エージェント、第二新卒向けエージェント
- 関連語: キャリアコンサルタント、ヘッドハンター、リクルーター
この手法の重みスコアの典型値は0.30〜0.40であり、6軸の中では最も高い基礎スコアが付与される。理由は、辞書的な言い換えは意味のずれが最も小さく、検索意図との乖離リスクが低いためである。
3-2. 法令・行政系展開
これはAI検索特有の展開軸であり、従来のSEOではほぼ考慮されてこなかった領域である。AIは法律用語、行政文書で使われる正式名称、省庁の分類体系を参照して、一般的な用語を公式な表現に変換する。
- 転職エージェント → 有料職業紹介事業者(職業安定法に基づく正式名称)
- 転職エージェント → 職業紹介事業(厚生労働省の分類体系)
- 派遣会社 → 労働者派遣事業者
- フリーランス → 個人事業主(税法上の分類)
行政系展開の重みスコアは0.20〜0.30程度であるが、信頼性の高い情報源(.go.jpドメイン等)からの情報取得時にはスコアが引き上がる傾向がある。これは、行政用語で検索した場合に見つかる情報は公的機関のものが多く、情報の信頼性が担保されやすいためである。
3-3. コーパス統計展開
大規模テキストコーパス(Common Crawl、Wikipedia、ニュース記事等)から統計的共起関係を抽出し、入力キーワードと頻繁に共起する語を候補として生成する手法である。
具体的には、PMI(Pointwise Mutual Information:自己相互情報量)やTF-IDFに基づいて、あるキーワードと統計的に有意な関係にある語を算出する。
「転職エージェント」に対するコーパス統計展開の結果例:
| 共起語 | PMIスコア | 出現頻度 | カテゴリ |
|---|---|---|---|
| 口コミ | 8.7 | 非常に高い | 評判系 |
| 評判 | 8.4 | 非常に高い | 評判系 |
| おすすめ | 7.9 | 高い | 推薦系 |
| ランキング | 7.6 | 高い | 比較系 |
| 年収 | 6.8 | 中程度 | 条件系 |
| 面談 | 6.5 | 中程度 | プロセス系 |
| 非公開求人 | 6.2 | 中程度 | 特徴系 |
3-4. 埋め込み近傍(意味ベクトル)展開
これはAI検索の中核技術の一つであり、単語や文をベクトル空間に埋め込み(embedding)、そのベクトル空間上での近傍探索によって意味的に近い概念を発見する手法である。
具体的には、BERT、Sentence-BERT、OpenAIのembedding API等で生成される高次元ベクトル(通常768〜1536次元)を用いて、コサイン類似度に基づく近傍探索を行う。
埋め込み近傍展開の重要な特性は、辞書に登録されていない新しい言い換えを発見できる点にある。例えば「人材マッチング」は従来のシソーラスには「転職エージェント」の同義語として登録されていない可能性が高いが、ベクトル空間上では近い位置に配置されるため、AIはこれを有効な言い換え候補として認識する。
3-5. パターン規則展開
形態素レベルでの表現の書き換えルールを適用する手法である。これは比較的単純なルールベースの変換だが、検索クエリの多様性を確保する上で重要な役割を果たす。
- 「おすすめ」→ 「満足度が高い」「評価が高い」「利用者に支持されている」
- 「人気」→ 「利用者数が多い」「登録者数が多い」「選ばれている」
- 「比較」→ 「違い」「差」「メリット・デメリット」
- 「使い方」→ 「利用方法」「活用法」「始め方」「登録手順」
- 「無料」→ 「費用がかからない」「0円」「料金不要」
3-6. 翻訳ピボット展開
これは最も意外性のある展開手法であり、一度別の言語(主に英語)に翻訳し、その翻訳結果を再度日本語に戻すことで、元のキーワードとは異なる表現を生成するプロセスである。
翻訳ピボットのプロセス:
- 「転職エージェント」→ 英語: “career change agent”, “recruitment agency”, “job placement service”
- 英語候補それぞれを日本語に再翻訳: 「キャリアチェンジ支援」「人材採用会社」「職業斡旋サービス」
- 元の日本語と異なる表現のみを候補として採用
この手法の重みスコアは0.10〜0.20と6軸の中では最も低いが、他の5軸では発見できない表現を生成できる点に価値がある。特に、日本語では一般的でないが英語圏では標準的な概念(例:「タレントアクイジション」= Talent Acquisition)を掘り起こすことができる。
技術的補足: 翻訳ピボットは「翻訳の不完全性」を逆に活用している。完璧な翻訳では元の表現と同じものが返されるだけだが、翻訳過程で生じる「意味のずれ」が新たな言い換え候補の源泉となる。これはback-translationとしてNLPの分野ではデータ拡張(Data Augmentation)の手法として広く知られている。
エビデンスの重みづけと選定アルゴリズム
6軸の言い換え展開によって生成された候補キーワード群に対して、AIは次にエビデンスの重みづけ(Evidence Scoring)を行う。これは単に各候補にスコアを付けるだけの単純な処理ではなく、複数のシグナルを統合的に評価する多段階のプロセスである。
4-1. ソーススコア(基礎信頼度)
各言い換え候補には、それがどの展開軸から生成されたかに基づく基礎信頼度(ソーススコア)が付与される。
重要なのは、これらのスコアは固定値ではない点である。クエリのドメイン(医療、法律、IT等)や意図の種類によって動的に調整される。例えば、医療関連のクエリでは法令・行政系のスコアが引き上げられ、エンタメ関連のクエリではコーパス統計のスコアが相対的に高くなる。
4-2. コンテキスト調整係数
ソーススコアに対して、以下の5つのコンテキスト調整係数が乗算される。
言い換え候補がユーザーの検索意図とどの程度一致するかを評価。意図から大きく逸脱する候補はスコアが下がり、意図を的確に捉えた候補はブーストされる。
当該キーワードで実際に検索した場合のSERP上位結果が、ユーザーの意図に合致しているかを評価。SEO上位に関連性の高いページが多いほどスコアが上がる。
検索結果に含まれるドメインの権威性を評価。.go.jp、大手メディア、学術機関等のドメインが多いほどスコアにプラスの補正がかかる。
新しいトレンドや最新情報を含むキーワードに対する加点。ニュース性の高いクエリほど鮮度の重みが増す。
4-3. 多様性ペナルティとMMR
最終的なクエリ候補の選出において、AIはMMR(Maximal Marginal Relevance)に基づく多様性ペナルティを適用する。これは、関連性が高くても既に選出された候補と意味的に重複する候補のスコアを下げることで、検索結果の多様性を確保する仕組みである。
このMMRにより、例えば「人材紹介会社」と「人材紹介サービス」のように意味がほぼ同一の候補は、一方が選出されるともう一方のスコアが大幅に減衰される。結果として、最終的に選出される20件のクエリは、意味的に幅広いカバレッジを持つことになる。
4-4. 最適組み合わせの選定プロセス
スコアリングが完了すると、AIは最終的に上位20件のキーワード組み合わせを選定する。この選定プロセスは単純なスコア順のソートではなく、以下の最適化問題として解かれる。
最適化の目的関数: 選出されたクエリ集合全体で、(1)ユーザー意図への網羅性が最大化され、(2)検索結果の多様性が確保され、(3)高品質なソースへの到達確率が最大化される——この3つの目的を同時に満たすキーワード組み合わせを選定する。
この最適化は、実質的にはサブモジュラ最適化の一種であり、貪欲法(Greedy Algorithm)によって近似的に解かれる。具体的には:
- スコアが最も高い候補を最初に選出する
- 次の候補を選出する際、MMRによる多様性ペナルティを適用した上で最高スコアのものを選ぶ
- このプロセスを20件に達するまで繰り返す
- SEO上位に表示されるキーワードを優先的に選出するバイアスが各ステップでかかる
なぜ「普通の検索と違う」と感じるのか
ここまでの解説で明らかになったように、AI検索で使われるキーワードは、従来のサジェスト・共起語・リンクリレーションから導かれるものではなく、辞書・行政・コーパス・意味ベクトル・規則・翻訳という多軸の言い換えから生成される。
この違いが、以下のような「AI検索特有の現象」を引き起こす。
5-1. マニアックな情報への到達
「こんなマニアックなものまで拾うのか」——これはAI検索を使ったユーザーが共通して感じる驚きである。この現象の原因は明確である。
従来の検索では、ユーザーが入力した1つのキーワードに対して1つのSERPが返される。つまり、ユーザーが「転職エージェント」と検索すれば、そのキーワードを含むページのみが表示される。
一方、AI検索では内部で20以上の言い換えクエリが実行される。その中には「有料職業紹介事業者」のような行政用語や、「タレントアクイジション」のような翻訳ピボット由来の表現も含まれる。結果として、通常のユーザーが絶対に検索しないキーワードでヒットするコンテンツまでAIは到達する。
5-2. SEO/AIOにおける実践的示唆
このロジックの理解から導かれる、SEO/AIOの実践的な施策方針は以下の通りである。
1つのページに、6軸すべてから生成されうる言い換えキーワードを自然な文脈で含める。特に行政用語・法令用語は見落とされがちだが、AIが高い信頼スコアで参照するため重要度が高い。
AIクローラはHTML構造を解析して情報を抽出する。適切な見出し階層、テーブル、リスト構造を用いることで、AIが情報を正確に取得しやすくなる。
AIはエビデンスの信頼性を重視する。データ、統計、引用元、専門家の見解等を明示的に記載することで、AIからのエビデンススコアが向上する。
AIのコンテキスト調整係数においてドメイン権威性は重要なファクターである。専門分野での一貫した情報発信、被引用の蓄積が長期的なスコア向上につながる。
結論:AI検索ロジックの本質
サイトキーワードを展開し、さまざまな業界で言い換えられるすべての組み合わせのうち、上位20件を選んで検索している。これがAIのWeb検索ロジックであり、従来のサジェスト・共起語・リンクリレーとは異なる「言い換えのロジック」によるSEOに変わっただけである。
ただし、「変わっただけ」とは言っても、その技術的深度は従来のSEOとは比較にならない。6軸のキーワード展開、多段階のスコアリング、MMRによる多様性制御、サブモジュラ最適化による組み合わせ選定——これらのプロセスを理解し、それぞれに対して適切な施策を講じることで初めて、AI検索時代のSEO/AIOにおいて成果を出すことが可能になる。
合同会社FIELDの見解
合同会社FIELDは、HTMLランダム性やN+1のツリーリンク構造など、SEOにおいて極めて重要な技術情報を保有しています。また、本記事で解説したAI検索ロジックに対する深い理解と、それに基づく具体的な実装技術を有しています。
しかし、はっきり申し上げます。
順位向上のために実行すべき明確な施策が存在していても、それを技術力や理解の不足により正確に実装できない会社が、SEOやAIOの順位を上げることはありません。
SEOもAIOも、理論を知っているだけでは成果は出ません。指示された通りに正確に実行できる技術力があって初めて、検索順位は動きます。
6軸のキーワード展開に対応したコンテンツ設計、エビデンススコアリングを意識した情報構造化、HTMLの最適化——これらすべてを正確に、一貫して実装できる技術力が、AI検索時代のSEO/AIOにおける最大の差別化要因です。
合同会社FIELDは、AI検索ロジックを理解した上で、それを正確に実装する技術力を提供します。 理論と実装の両輪を備えた施策により、従来のSEOでは到達できなかった成果を実現します。