全体アーキテクチャ
本システムは大きく4つのレイヤーで構成されています。ユーザーからの質問が各コンポーネントを経由し、ナレッジベースの情報を加味した回答を生成するまでの全体像を示します。
Open WebUI
Ollama
llama.cpp
H2O LLM Studio
Qdrant
Tika
Docling
1H2O LLM Studioでモデルをファインチューニング
H2O LLM Studioは、コードを一行も書かずにLLMをファインチューニングできるGUIツールです。
社内データやドメイン固有のデータを使い、ベースモデルを自社用途に特化させます。
1-1. Datasetの準備とアップロード
H2O LLM Studioが期待するデータセット形式は、CSV/TSVで以下のカラムを含む構成です:
| カラム名 | 説明 | 例 |
|---|
instruction | モデルへの指示(システムプロンプト的役割) | 「以下の質問に日本語で答えてください」 |
input | ユーザーの入力・質問 | 「RAGとは何ですか?」 |
output | 期待される応答 | 「RAGは Retrieval-Augmented Generation の略で…」 |
Tips: データセットの品質がファインチューニングの結果を大きく左右します。ノイズの少ない、一貫性のあるデータを準備しましょう。最低でも数百件のペアを用意することを推奨します。
1-2. Experimentの作成と設定
データセットをアップロードしたら、次にExperiment(訓練実験)を作成します。ここが最も設定項目が多く、理解が必要なステップです。
主要な設定項目の解説
| カテゴリ | 設定項目 | 説明 |
|---|
| Dataset | Prompt Column | 入力(質問)が含まれるカラム名を指定 |
| Answer Column | 出力(回答)が含まれるカラム名を指定 |
| LLM Backbone | Base Model | ファインチューニングのベースとなるモデル(Llama, Mistral等) |
| LoRA | メモリ効率の良い学習手法。フル学習よりGPUメモリが少なくて済む |
| Max Length | 入力トークンの最大長。長いほどメモリを消費 |
| Training | Learning Rate | 学習率。大きすぎると発散、小さすぎると収束しない |
| Epochs | データセット全体を何回繰り返し学習するか |
| Batch Size | 一度に処理するサンプル数。GPUメモリに依存 |
注意: LoRAのrank(r)値を大きくするとモデルの表現力は上がりますが、過学習のリスクも高まります。まずは r=8, alpha=16 から始めて、結果を見ながら調整しましょう。
1-3. 訓練の実行とモデルのエクスポート
Experimentを開始すると、H2O LLM Studioがトレーニングを自動的に実行します。完了後、モデルをエクスポートします。
# H2OからエクスポートしたモデルをGGUF形式に変換
python llama.cpp/convert_hf_to_gguf.py \
–model ./h2o_exported_model \
–outfile ./model.gguf
# 量子化(モデルサイズを削減)
./llama.cpp/llama-quantize ./model.gguf ./model-Q4_K_M.gguf Q4_K_M
2Ollamaにモデルを登録する
GGUFファイルをOllamaに登録し、APIサーバーとして利用可能にします。「モデル工場」でH2Oのexperimentを選択し、Ollamaモデル名を入力するステップです。
# 1. Modelfile を作成
cat << ‘EOF’ > Modelfile
FROM ./model-Q4_K_M.gguf
PARAMETER temperature 0.3
PARAMETER top_p 0.9
PARAMETER repeat_penalty 1.2
SYSTEM “””あなたは社内ナレッジに精通したAIアシスタントです。
正確で簡潔な回答を心がけてください。”””
EOF
# 2. Ollama にモデルを登録
ollama create my-company-model -f Modelfile
# 3. テスト実行
ollama run my-company-model “こんにちは、テストです”
# 4. API として利用可能に(デフォルト: localhost:11434)
curl http://localhost:11434/api/chat -d ‘{
“model”: “my-company-model”,
“messages”: [{“role”: “user”, “content”: “テスト”}]
}’
Tips: Ollamaはバックグラウンドでllama.cppを使用してモデルの推論を行います。GGUFフォーマットを直接読み込むため、追加の変換は不要です。
3ドキュメント処理パイプライン(Tika / Docling)
RAGで利用するナレッジベースのドキュメントを、LLMが理解できるテキスト形式に変換します。PDF、Word、Excel、PowerPointなど多様な形式に対応するため、TikaとDoclingを活用します。
Tika vs Docling の使い分け
| 特徴 | Apache Tika | Docling |
|---|
| 対応形式 | 1000+形式(汎用的) | PDF中心(高精度) |
| テーブル抽出 | 基本的なサポート | 構造を保持した高精度抽出 |
| OCR | Tesseract連携 | 内蔵OCRエンジン |
| レイアウト認識 | 限定的 | 高精度なレイアウト解析 |
| 実装言語 | Java (REST API提供) | Python |
| 推奨ユースケース | 多様なファイル形式を一括処理 | PDFの高精度テキスト抽出 |
# — Tika: REST APIでドキュメントをテキスト抽出 —
# Tikaサーバー起動
docker run -p 9998:9998 apache/tika
# テキスト抽出
curl -T document.pdf http://localhost:9998/tika –header “Accept: text/plain”
# — Docling: PDFの高精度パース —
pip install docling
# Python での利用例
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert(“document.pdf”)
print(result.document.export_to_markdown())
4Qdrant ベクトルデータベース
ドキュメントから抽出・分割されたテキストチャンクをベクトル化して保存し、類似検索を可能にするのがQdrantの役割です。RAGの「Retrieval」部分の中核を担います。
# Qdrant サーバー起動
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant
# Python でコレクション作成 & ドキュメント登録
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
client = QdrantClient(host=”localhost”, port=6333)
# コレクション作成(ベクトル次元はEmbeddingモデルに依存)
client.create_collection(
collection_name=”knowledge_base”,
vectors_config=VectorParams(size=768, distance=Distance.COSINE)
)
# ドキュメントチャンクをベクトル化して登録
client.upsert(
collection_name=”knowledge_base”,
points=[
PointStruct(id=1, vector=embedding_vector, payload={“text”: “chunk text…”}),
# …
]
)
# 類似検索
results = client.search(
collection_name=”knowledge_base”,
query_vector=query_embedding,
limit=5
)
5Open WebUI でRAGチャットを構築
すべてのコンポーネントを統合するフロントエンドがOpen WebUIです。ナレッジベースの作成、ファイルのアップロード、モデルの設定をGUIで行えます。
5-1. ナレッジベースの作成
5-2. Open WebUI のセットアップ手順
# Open WebUI をDocker で起動(Ollama と連携)
docker run -d -p 3000:8080 \
–add-host=host.docker.internal:host-gateway \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
-e RAG_EMBEDDING_MODEL=sentence-transformers/all-MiniLM-L6-v2 \
-e VECTOR_DB=qdrant \
-e QDRANT_URI=http://host.docker.internal:6333 \
-v open-webui:/app/backend/data \
–name open-webui \
–restart always \
ghcr.io/open-webui/open-webui:main
設定手順まとめ
- ナレッジベース作成: 管理画面 → ワークスペース → ナレッジベース → 「New Knowledge」をクリック。名前と説明を入力して作成。
- ファイルアップロード: 作成したナレッジベースの編集画面を開き、RAGに使いたいドキュメント(PDF, DOCX等)をドラッグ&ドロップまたはファイル選択でアップロード。自動的にチャンク分割・ベクトル化される。
- モデル作成: ワークスペース → モデル → 「New Model」。Ollamaで登録したモデル名を指定し、先ほど作成したナレッジベースを紐付ける。
- チャット開始: チャット画面でモデルを選択して質問すると、自動的にRAG検索が行われ、関連ドキュメントの情報を加味した回答が生成される。
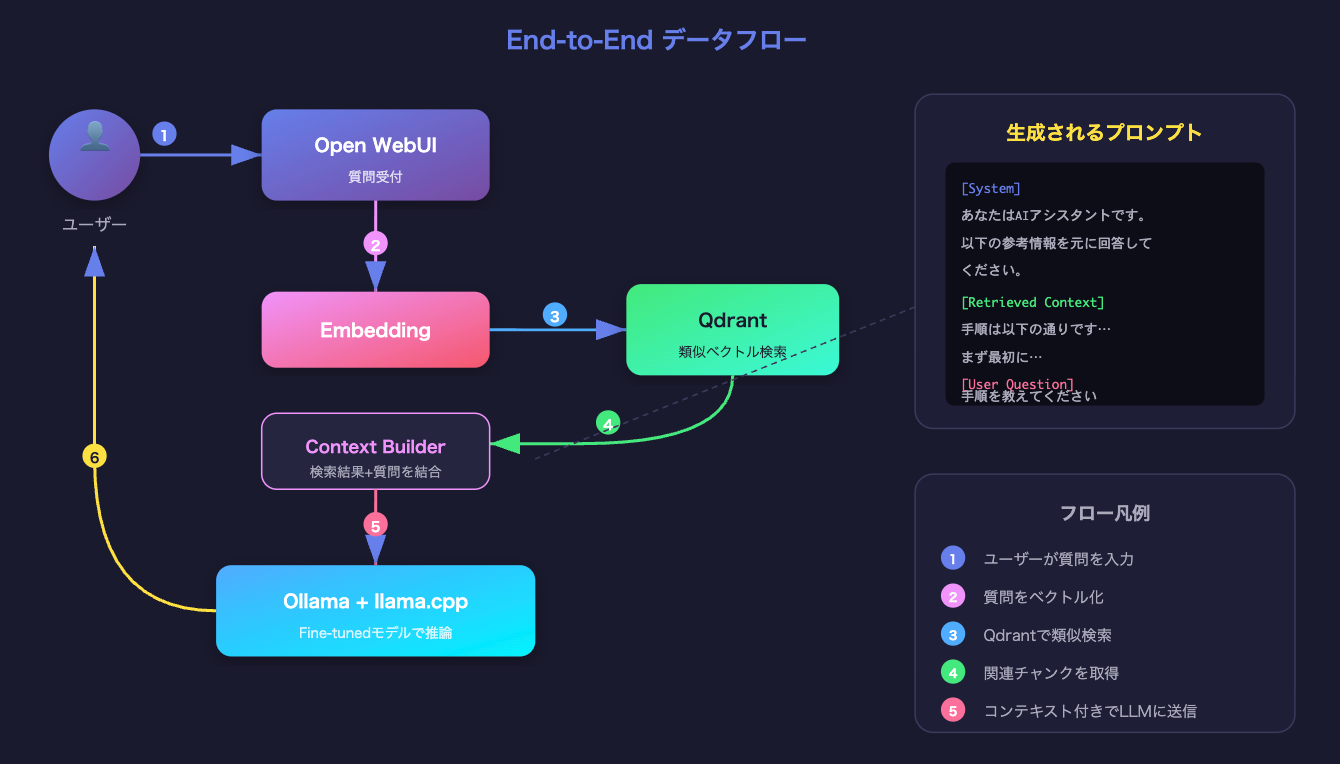
6全体データフロー
最後に、ユーザーが質問を入力してから回答が生成されるまでの全体的なデータの流れを確認しましょう。