
「airbnbで、ある住所の部屋の全ての金額を取得するクローラー作って欲しいんだけど、今日中に作れる?」
と言われた時。
pythonのbeautiful soupなら可能です。
では、早速作ってみましょう。
その前に実行環境は最近はgoogle colaboratoryというものがありますので、
それを使っていきます。
ここのfileから新規作成をしてクラウド上でpythonを動かすことが可能です。
ではpythonでbeautiful soupを使ってクローリングをしていきます。
まずは、importでおあつらえなものを読み込みます。
# BeautifulSoupを読み込む
from bs4 import BeautifulSoup
import requests
import urllib.parse
#スリープをインポート
from time import sleep
#今回のサイトのドメイン
domain = "https://www.airbnb.com"
#今回の地域(ターゲット)
target_area = "東京都新宿区上落合1丁目"
#encode
target_area_enc = urllib.parse.quote(target_area)target_areaに入力した住所をクローリングするようにしてみました。
airbnbで上落合1丁目あたりのURLはどうなってるのかを調べてみましょう。

URL構造をみると共に、取得する金額の場所も確認。
# WebサイトのURLを指定
target_url = domain+"/s/"+target_area_enc+"/homes?tab_id=all_tab&refinement_paths%5B%5D=%2Fhomes&source=structured_search_input_header&search_type=search_query&display_currency=JPY"
print("クローリング開始URL(住所検索のURL)")
print(target_url)
print(" ")
print(" ")
print(" ")こんな感じでしょうか。
ああそうだ..ページネーションの最後の数字のHTMLのclassを把握して
何ページあるかを取得して全てのページを回遊しないといけなかったですね。

# Requestsを利用してWebページを取得する
html = requests.get(target_url)
# パーサーの準備
soup = BeautifulSoup(html.text, 'html.parser')
for link in soup.findAll("a"):
if "/rooms/" in link.get("href"):
print(domain + link.get('href'))
print("このページの部屋の金額")
price_arr = soup.find_all("span", class_="_1p7iugi")
for price in price_arr:
print(price.contents[1])
#全部で何ページあるか
two = soup.find(class_="_i66xk8d")
last_page = two.find_previous_sibling().a.string
print("この検索ページは"+last_page+"ページ存在する")
last_page = int(last_page)
これで、金額の取得と、
一番後ろのページネーションの番号を取れたのでその数だけ
ページネーションをクリックしつつ
金額を取得してけばいいかなと思います。
# BeautifulSoupを読み込む
from bs4 import BeautifulSoup
import requests
import urllib.parse
#スリープをインポート
from time import sleep
#今回のサイトのドメイン
domain = "https://www.airbnb.com"
#今回の地域(ターゲット)
target_area = "東京都新宿区上落合1丁目"
#encode
target_area_enc = urllib.parse.quote(target_area)
# WebサイトのURLを指定
target_url = domain+"/s/"+target_area_enc+"/homes?tab_id=all_tab&refinement_paths%5B%5D=%2Fhomes&source=structured_search_input_header&search_type=search_query&display_currency=JPY"
print("クローリング開始URL(住所検索のURL)")
print(target_url)
print(" ")
print(" ")
print(" ")
# Requestsを利用してWebページを取得する
html = requests.get(target_url)
# パーサーの準備
soup = BeautifulSoup(html.text, 'html.parser')
for link in soup.findAll("a"):
if "/rooms/" in link.get("href"):
print(domain + link.get('href'))
print("このページの部屋の金額")
price_arr = soup.find_all("span", class_="_1p7iugi")
for price in price_arr:
print(price.contents[1])
#全部で何ページあるか
two = soup.find(class_="_i66xk8d")
last_page = two.find_previous_sibling().a.string
print("この検索ページは"+last_page+"ページ存在する")
last_page = int(last_page)
if last_page>1:
print("2ページ以上あるときはページングのURLを全部取得する")
#2ページ目のリンク構造の取得
page2linktag_raw = soup.find(attrs={"data-id":"page-2"}).a.get("href")
split = page2linktag_raw.split('&items_offset=')
page2linktag = split[0]
if split[1] in "&query=":
#後半に&query=があるってことはクエリがoffset以降も存在するということなので連結する
last_query_raw=split[1].split('&query=')
last_query="&query="+ last_query_raw[1]
else:
last_query = ""
for i in range(last_page):
page = i + 2
print(" ")
print (str(page) + "ページ目のクローリングURL")
if page > 1:
offset = (page - 1)*20
else:
offset =""
query_offset = "&items_offset=" + str(offset)
pagenation_link = domain + page2linktag + query_offset
print(pagenation_link)
print("↓↓↓↓"+str(page)+"ページ目の部屋↓↓↓↓↓↓")
#ページングのページもパース準備
html2 = requests.get(pagenation_link)
soup2 = BeautifulSoup(html2.text, 'html.parser')
next_page_html = requests.get(pagenation_link)
for next_link in soup2.findAll("a"):
if "/rooms/" in next_link.get("href"):
print(domain + next_link.get('href'))
print(" ")
print(str(page)+"ページ目の金額")
price_arr2 = soup2.find_all("span", class_="_1p7iugi")
for price2 in price_arr2:
print(price2.contents[1])
こんな感じでしょうか。
では、動くか実行してみます。
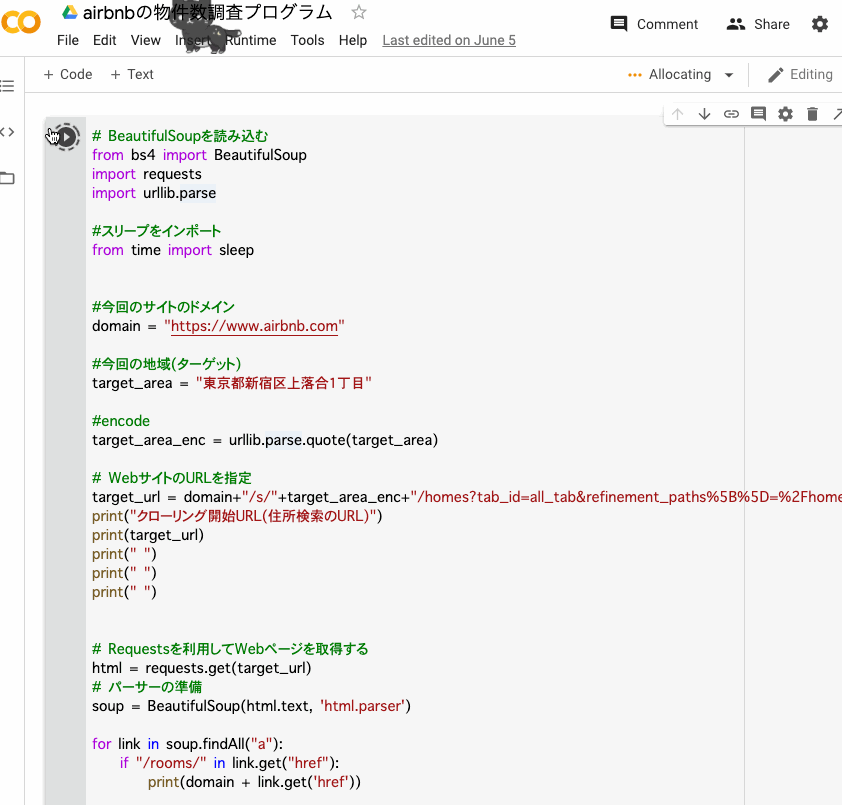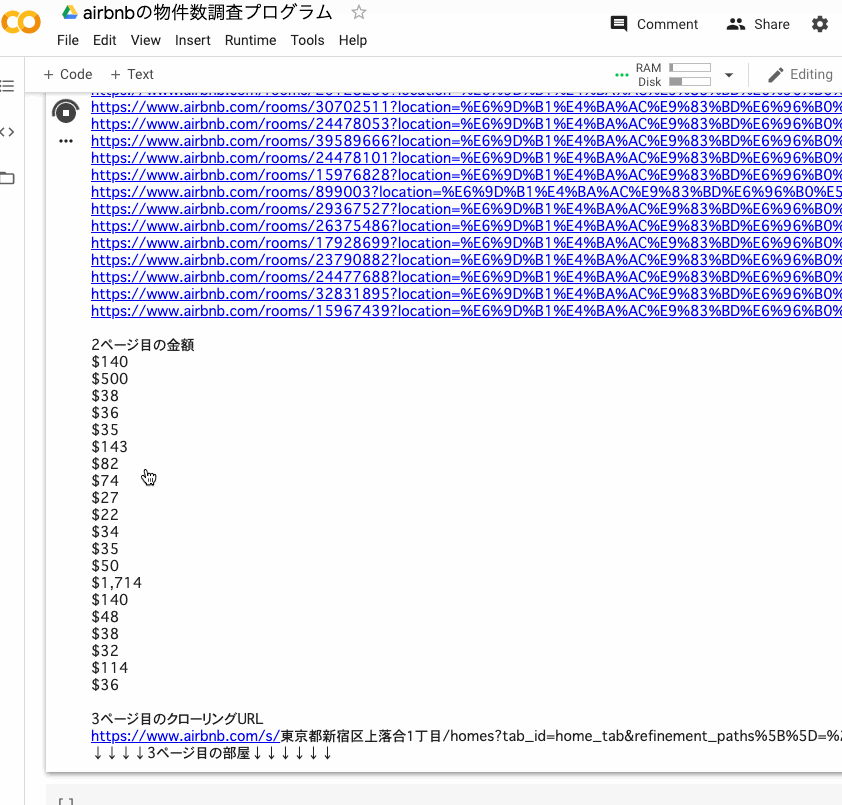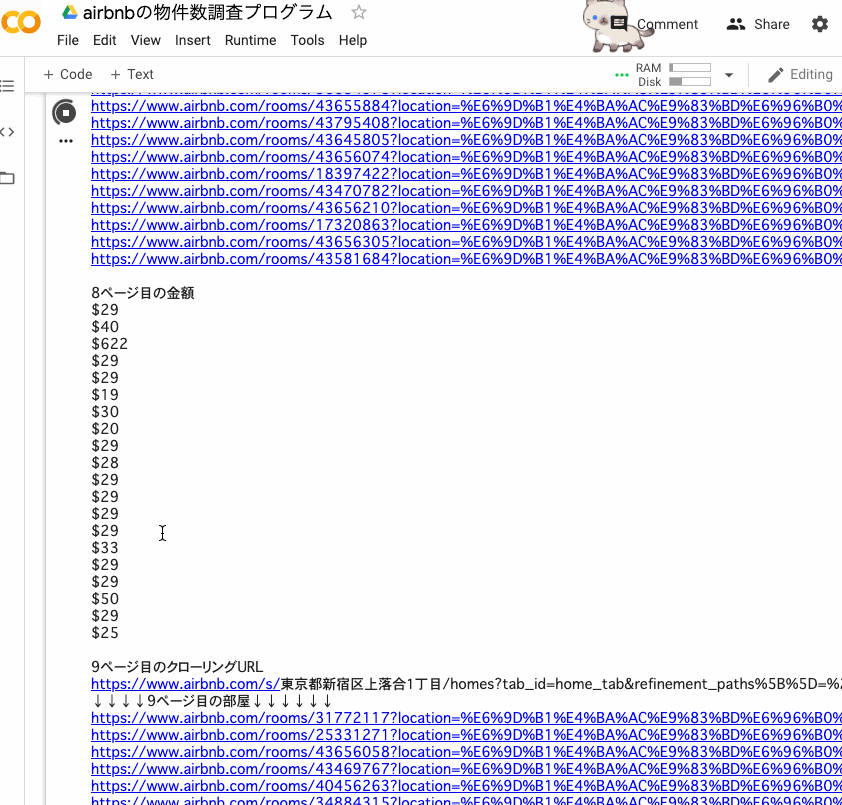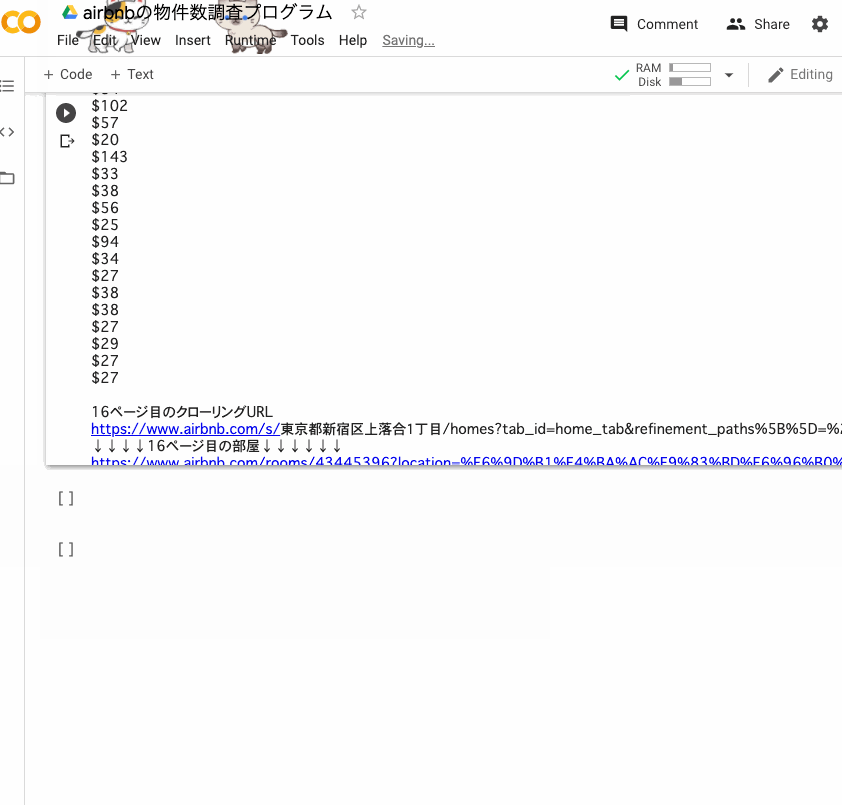
取れてますね。
同じ容量で全国の市区町村マスタでeachしてあげれば
全国のairbnbの部屋の金額を取得することも可能です。
ただ、それをやろうとすると当然のようにIPブロックされますので
https://my.apify.com/proxy
このようなサービスを利用すると良いです。
また、弊社ではIPを分散することにより、
飲食系では食べログ、ぐるなび、ひとさら、rettyの全ての飲食店情報を、
人材系の20メディア、それぞれ全情報をクローリング仕切ることが可能であることも確認しています。
(※商用利用していません)