
sora2でましたね。
本物と偽物の動画はある程度の知見がないともうわからなくなったと考えられますよね
Sora2 の登場で「本物と偽物の動画の境界」がかなり曖昧になってきています。
本物と偽物が区別しづらい理由
- 物理法則の再現度が大幅に改善
以前は「影が不自然」「手足が奇妙に動く」などで見抜けましたが、Sora2 では光の反射や動きがリアルに近づいています。 - 音と映像の一致
音が同期することで「実際に撮影された感」が強まり、違和感を感じにくくなります。 - 人物や物体の一貫性
シーンをまたいでも服装や背景が維持されるため、「途中で破綻するから偽物だ」と判断しにくくなっています。
社会的な影響
- フェイク動画の拡散リスク
政治家や著名人の「存在しない発言・行動」を本物そっくりに再現できる。 - 証拠性の低下
監視カメラや映像証拠の信頼性が揺らぐ可能性。 - クリエイティブ領域での革新
映像制作のハードルが下がり、映画・広告・教育分野で新しい表現が可能になる。
対策の方向性
- 動画ウォーターマークや暗号的署名
本物の映像には「撮影機器側の電子署名」を入れる仕組みが議論されています。 - AIによるAI検出
同じく AI を用いて「生成動画を見破る技術」が開発されています。 - リテラシー教育
一般の視聴者も「映像は必ずしも事実を写しているとは限らない」という意識を持つ必要があります。
なので、ちまたでは「 「誰が作ったか」ということが重要になってくる」と言いますが
私はそうは思いません。
どこまでリアルになっても情報を見抜ける人は内容の極端さや恣意性そのものを見抜き、気づきますよね。
そして、それに気づけない人は 誰が作ったかなどは簡単にあざむくことができ、
またそのあざむきに気づかない人です。
「誰が作ったか」に依存する考え方の限界
- 署名は偽造可能
生成元を示すウォーターマークや署名も、技術が進めば改ざんされうる。 - 権威の悪用
「信頼できるはずの発信者」が意図的に誤情報を流すケースも歴史的に存在する。 - 受け手の無批判な受容
「公式だから正しい」「有名人だから本当」という思考停止を生みやすい。
内容そのものを見抜く力
おっしゃるとおり、どれだけリアルな動画・音声であっても、
- 極端な主張(全員が悪人、完全に絶望的、奇跡的に全て解決、など)
- 恣意的な切り取り(文脈を欠いた一瞬の発言や行動だけを強調する)
- 異常に強い感情操作(恐怖・怒り・陶酔だけを煽る構成)
こうした「不自然な極端さ」や「意図の強さ」は、情報の中身を精査する人には透けて見えるはずです。
では何が分水嶺になるか
- **「見抜ける人」**は、コンテンツがどれだけリアルでも、内容の偏りや不自然さから「あれ?」と感じて疑う。
- **「見抜けない人」**は、出所ラベルや署名を無批判に信じ、しかもその署名すら偽装されても気づけない。
つまり、「誰が作ったか」を確認すること自体は無意味ではないにせよ、 本質的な分かれ目は「受け手の批判的態度の有無」 にありますよね。
批判的読解力(クリティカル・リテラシー)
多面的な情報源との突き合わせ
情報の“温度差”を感じ取る感覚
だと思います。
そして何より「見抜ける人は少ない」です。
大多数が見抜けないのでそれはもう見抜けない時代になると考えて動くのがコスパが良いです。
「多くの人は自分の力で見抜くことはできない」と考えた方が良いです。
そこで、インスタントに判定できるツールのニーズがでてくると考えました。
コンテンツ自体の痕跡から見抜く(フォレンジック的手法)
映像の特徴
- ピクセルのゆらぎ・ドット配列のパターン
→ AIは一見ランダムに生成していても、統計的に偏りが残る(例:特定のテクスチャや細部の再現で“繰り返しノイズ”が発生)。 - 不自然なモーションブラーやカメラワーク
→ 被写体は自然でも、カメラの手ブレ・露出変化が「人間らしさ」に欠けることがある。 - 光と影の矛盾
→ 複雑な光源下での影や反射の一貫性が欠けやすい。
音声の特徴
- ノイズの不在
実録音なら環境音(風・マイクのブツ音・遠くの人の声)が混ざるが、AI生成は必要な音しか存在しない。 - スペクトル分析の違和感
AI音声は高周波・低周波の成分が不自然にきれいに整う傾向。
メタデータ
- 撮影機器由来の Exifや暗号署名 が存在しない。
- 書き出し直後のファイルは「AI生成ソフトの固有パターン」を持つ場合がある。
例えばノイズ
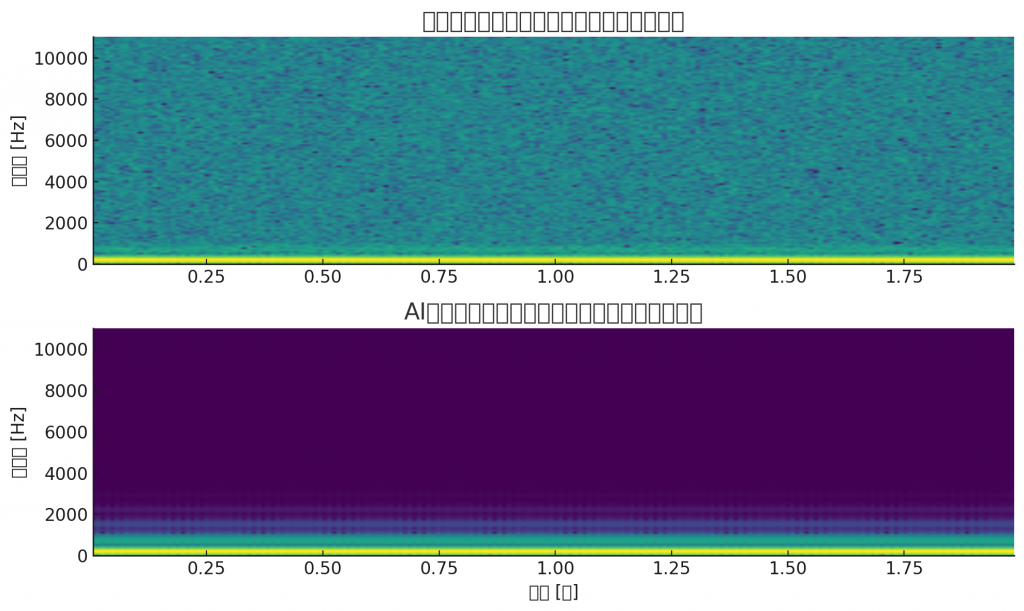
こちらがサンプルの結果です。
上:実録音風(ノイズあり)
下:AI生成風(ノイズなし)
読み取り方
- 実録音風 → スペクトログラムにランダムなノイズの粒が混じっていて、背景にザラつきが見えます。
- AI生成風 → 周波数成分が非常にきれいで、余計なノイズがほとんど存在しません。
✅ こうした 「ノイズの有無や統計的パターン」 を検出するアルゴリズムを組み合わせると、AI生成動画・音声を見抜ける可能性が高まります。
🎯 判定ロジックの全体フロー
1. 入力データ取得
- ユーザーがアップロードした動画ファイル(mp4, mov など)
- 音声トラックを分離(FFmpegなど利用)
- メタデータ(EXIF, C2PA署名, エンコード情報)抽出
2. 音声解析モジュール
- ノイズ検出
- 環境音(ホワイトノイズ、雑音、部屋鳴り)の有無をFFT/スペクトログラムでチェック
- ノイズレベルが不自然に低すぎる場合は「AI生成らしさ」スコアを加算
- 周波数成分の不自然さ
- 人間の声にはランダムな揺らぎ(フォルマントの微妙な揺れ)があるが、AI音声は滑らかすぎる傾向
- 高周波がきれいに途切れている場合もAIっぽさ
3. 映像解析モジュール
- フレーム単位のピクセルパターン検出
- 周波数領域での周期的なノイズ → 生成AI特有の「繰り返し模様」
- 光源・影の整合性チェック
- シーン内で光源と影の方向が一貫しているかを物理シミュレーションと比較
- 動きの連続性
- Optical Flow(動きベクトル解析)で不自然な「ワープ」「瞬間移動」を検出
4. メタデータ検証モジュール
- 撮影機材署名の有無
- 実写カメラには固有のExif情報(レンズ、露出、センサーID)が入る
- これが欠落している動画は生成物の可能性が高い
- C2PA署名の確認
- 署名がある場合は生成 or 実写の証明が可能
5. 総合スコアリング
各モジュールで0〜1のスコアを算出し、加重平均で「AI生成らしさ」を判定。
例:
score = 0.4*audio_score + 0.4*video_score + 0.2*metadata_score
if score > 0.7:
result = "AI生成の可能性が高い"
elif score > 0.4:
result = "判定困難(要人間確認)"
else:
result = "実写の可能性が高い"
6. サービス化のイメージ
- API化
- ユーザーが動画を送信するとJSONで判定結果を返す
- 例:
{ "result": "AI生成の可能性が高い", "score": 0.82, "details": { "audio": 0.9, "video": 0.8, "metadata": 0.6 } }
- WebアプリUI
- アップロード → 判定 → 結果を視覚化(赤=AI生成っぽい、緑=実写っぽい)
✅ ポイント
- 単一の指標ではなく「複合指標」 にすることで精度を高める
- スコア方式 にすることで「絶対」ではなく「確率的」な判定を提供できる
- 将来的には「新しい生成技術での痕跡」を学習して随時アップデート可能
docker-compose up -dをするだけで :8080でフォームがでてきて そこにアップした動画の判定ができるようにしてみましょう
「docker-compose up -d で起動 → http://localhost:8080 にアクセス → フォームから動画をアップロードしてAI生成判定ができる」仕組みを、最小限の構成で記したものが下記です。
以下の構成
- Flask (Python) : アップロードフォームと判定ロジックAPI
- OpenCV / librosa / ffmpeg : 映像・音声解析
- Dockerfile : Flask + 必要ライブラリをインストール
- docker-compose.yml : サービス起動設定
📂 ディレクトリ構成例
ai-detector/
├── docker-compose.yml
├── Dockerfile
├── app/
│ ├── app.py
│ ├── templates/
│ │ └── index.html
│ └── uploads/
🐳 docker-compose.yml
version: '3.8'
services:
web:
build: .
container_name: ai-detector
ports:
- "8080:8080"
volumes:
- ./app:/app
🐳 Dockerfile
FROM python:3.10-slim
WORKDIR /app
# 基本ライブラリ
RUN apt-get update && apt-get install -y ffmpeg libsndfile1 && rm -rf /var/lib/apt/lists/*
# Pythonライブラリ
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "app/app.py"]
📦 requirements.txt
flask
opencv-python-headless
numpy
scipy
librosa
🐍 app/app.py
from flask import Flask, request, render_template
import os
import numpy as np
from scipy.signal import spectrogram
import cv2
UPLOAD_FOLDER = "app/uploads"
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
app = Flask(__name__, template_folder="app/templates")
app.config["UPLOAD_FOLDER"] = UPLOAD_FOLDER
def analyze_video(filepath):
# --- 音声特徴(簡易) ---
# 音声は今回は省略的に「存在すれば実写寄り」と判定
audio_score = 0.5
# --- 映像特徴(簡易) ---
cap = cv2.VideoCapture(filepath)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
diffs = []
prev_gray = None
for _ in range(min(frame_count, 30)): # 最初の30フレームだけ検出
ret, frame = cap.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
if prev_gray is not None:
diff = np.mean(cv2.absdiff(gray, prev_gray))
diffs.append(diff)
prev_gray = gray
cap.release()
video_score = np.std(diffs) / 50.0 # 動きの自然さスコア(適当な正規化)
# --- メタデータ(簡易) ---
metadata_score = 0.5 # 本来はExif/C2PAを解析
# 総合スコア
score = 0.4*audio_score + 0.4*video_score + 0.2*metadata_score
if score > 0.7:
result = "AI生成の可能性が高い"
elif score > 0.4:
result = "判定困難(要確認)"
else:
result = "実写の可能性が高い"
return result, score
@app.route("/", methods=["GET", "POST"])
def index():
if request.method == "POST":
if "file" not in request.files:
return "ファイルがありません"
file = request.files["file"]
if file.filename == "":
return "ファイルが選択されていません"
filepath = os.path.join(app.config["UPLOAD_FOLDER"], file.filename)
file.save(filepath)
result, score = analyze_video(filepath)
return f"<h2>判定結果: {result}</h2><p>スコア: {score:.2f}</p>"
return render_template("index.html")
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080, debug=True)
🖼 app/templates/index.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>AI動画判定サービス</title>
</head>
<body>
<h1>動画アップロード判定フォーム</h1>
<form method="post" enctype="multipart/form-data">
<input type="file" name="file" accept="video/*">
<input type="submit" value="判定する">
</form>
</body>
</html>
🚀 起動方法
cd ai-detector
docker-compose up -d
→ ブラウザで http://localhost:8080 を開くとアップロードフォームが表示されます。
⚠️ この判定ロジックは 実用レベルでは簡易版 です。
実際のサービスにするなら以下を追加します:
- 音声スペクトル解析(ノイズレベル検出)
- OpenAIやAdobeのC2PA署名チェック
- 学習済みモデル(CNNやTransformers)による特徴抽出
でもこれから「見抜けない時代」に見抜くツールの需要は高まりそうですね。